D1.1 Technology survey: Prospective and challenges - Revised version (2018)
2 Data
2.3 ICT support and technologies for data management
A large variety of heterogeneous physical devices are used to collect water related data. Their connection with other components of the hydroinformatics platforms uses several technologies, the most recent one being the Internet of Things. This approach ensures the integration of data sources in the Internet by associating a unique identifier with each device and a semantic communication with other Internet components. IoT is already used in water related applications (see The role of IoT in sensing and communication).
Usually, data are received in real-time from the source and are most valuable at the time of arrival. This is why the analytics that process in real time large-scale stream data are used in many water related applications (see Streaming data analytics).
Pre-processing is essential in the data pipeline system because it takes an input of uncertain, missing or error-prone data and transforms it into reliable information. This can be done to filter and eliminate useless data or simply to reduce the overall amount of data that needs to be analysed. The most important aspect of data cleaning refers to the cleaning of time-series. This data is usually produced by sensors, which monitor different parameters of water flow or water consumption. Regression models exploit continuity and correlations between different sampling processes. The dependency of one variable (e.g. time) is computed to another (sensor values) in order to build a regression curve, which is then used as the standard (see Data cleaning).
Today the Internet represents a big space where great amounts of information are added every day. Large datasets of information is indisputable being amassed as a result of our social, mobile, and digital world. We are not far from the time when terms like PetaByte, ExaByte, and ZettaByte will be quite common. However, in the Big Data era, storing huge amounts data is not the biggest challenge anymore. Today researchers struggle with designing solutions to understand the Big amount of Data available. Efficient parallel/concurrent algorithms and implementation techniques are the key to meeting the scalability and performance requirements entailed by scientific data analyses. Challenges such as scalability and resilience to failure are already being addressed at the infrastructure layer. Applications need fast movement and operations on that data, not to mention support to cope with an incredible diversity of data. Big data issues also emerge from extensive data sharing, allowing multiple users to explore or analyses the same data set. All these demand a new movement - and a new set of complementary technologies. Big Data is the new way to process and analyse existing data and new data sources (see Processing, storing, and sharing large amount of data).
Up until recently Google, Amazon and Microsoft were the main actors capable to handle big data, but today new actors enter the Big Data stage. At the forefront, Google uses one of the largest dataset to discover interesting aspects to improve their services. MapReduce, their novel computing model, provoked the scientists to rethink how large-scale data operations should be handled (see MapReduce programing model).
Later on, the MapReduce community is migrating high-level languages on top of the current interface to move such functionality into the run time (see Other solutions related to MapReduce).
Sharing the data is another challenge for Big Data applications, besides processing. With all the BigData tools and instruments available, we are still far from understanding all the complexities behind processing large amounts of data (see Sharing the data).
The role of IoT in sensing and communication [top]
Internet of Things (IoT) is a network connecting together diverse physical devices, from sensors, to actuators, vehicles and even buildings. It proposes new methods to connect and access information using device2device communication protocols, developing paradigms such as smart objects, and the addressing to devices over Web services. More recently, IoT was introduced as an infrastructure for collecting data from the most diverse kind of devices in water monitoring applications, and dealing with the analyse of information over specialized IoT platforms such as InfluxData. Several examples of applications of IoT in water management stand up:
- Smart irrigation with IoT: Smart irrigation replaces existing irrigation controllers (which are just simple timers), with cloud enabled smart irrigation controllers that apply water based on plant need (i.e., type of crop) and weather. Moreover, with flow sensors and real-time alerts, property managers and landscape contractors can be alerted the second something goes awry, which if your site has any significant landscape at all, you know this can happen quite frequently. Examples of such systems: HydroPoint’s WeatherTRAK® smart irrigation system.
- Smart water meters with IoT: A smart water meter (device) can collect usage data and communicate it wirelessly to the water utility company, where analytics software reports the results on a web site to view. Examples of such systems: One of the largest pilot programs of smart meters and related water management software platforms (a smart water management network) is in San Francisco. Water consumption is measured hourly and data is transmitted on a wireless basis to the utility four times a day. Both the utility and customers can track use. A pilot program in the East Bay Municipal Water District, which targets mostly single-family homes, provides a daily update of hour-by-hour consumption via a website. Consumers can be alerted, for example, by email or phone call, when water use exceeds a specified limit or when a meter indicates continuous running water for 24 hours. A customer can further view the data as it comes in, as well as compare their numbers with past use and city averages. The usage data should eventually result in alerts for leaks (by comparing how the readings in consecutive water meters).
Determining water demand in a city: One of the crucial challenges of water management as well as conservation in a city is to determine the amount of water that any particular city is going to utilize during the next day. This can be calculated to precision with the use of predictive analytics. Recently, IoT was employed for this purpose, where dedicated platforms keep a track on the history of water consumption in the city on any given day. Based on the historical data collected and analysed by predictive analytics and combined with the consideration of special events, holidays, as well as the weather in that city, we can determine the amount of water that the entire population is going to consume in one day. The Internet of Things technology also helps in scheduling the maintenance as well as shutdown of pumps on a regular basis. There are optimization techniques, which can beforehand convey to the residents of a city regarding the unavailability of water during any particular point of time. This helps the water regulation authorities in not only meeting the adequate water demands in a city; rather it also aids in the conservation of resources and energy.
Streaming data analytics [top]
Processing and reasoning must be done in a real-time fashion. Efficient methods for streaming need to be considered as well as robust algorithms that must analyse the data in one pass since it is usually not possible to store the entire history of data. For example, applications that trigger alerts are time-sensitive and the time of response may be significantly influenced by the large number of monitored devices.
When considering Big Data analytics most of the data is received in real-time and is most valuable at the time of arrival. This is the main motivation behind the increased interest in the field of large-scale stream processing. Some of the earliest academic systems to handle streaming-data analytics were Aurora, STREAM, Borealis and Telegraph. They first introduced the concepts of sliding windows and incremental operators.
One of the major innovations of this field is the ability to run continuous queries that produce different results as new data arrives. Some of the major research challenges include fault tolerance.
There have been a number of recent systems that enable streaming processing with the use of high-level APIs.
Table 1. Comparison of big data messaging systems.
|
System |
Characteristics |
Drawbacks |
|
TimeStream [Qian, 2013] |
|
|
|
MillWheel [Akidau, 2013] |
|
|
|
MapReduce Online [Condie, 2010] |
|
|
|
Meteor Shower [Wang, 2012] |
|
|
|
iMR [Lologhetis, 2011] |
|
|
|
Percolator [Peng, 2010] |
|
|
A recent framework Spark has gained a lot of attention due to its different approach and increased performance. Its authors claim in [Zaharia, 2014] that Spark is 20 times faster than Hadoop for iterative applications and can process 1TB in about 5-7 seconds.
The key concept in Spark is represented by RDDs [Zaharia, 2012] (resilient distributed datasets). They consist of a restricted form of shared memory, which is based on coarse-grained operations and transformations (e.g. map, filter, join) to the shared state, as opposed to other systems which process fine-grained updates.
By applying the same operations to many data item sets it is possible to log the transformations and compute the lineage for each RDD, instead of the actual data. An RDD has enough lineage information to compute its partitions from stable storage. RDDs can express cluster programming models such as map-reduce, DryadLINQ, Haloop, Pregel or Sql and allow a more efficient fault tolerance than previous systems but are restricted to applications that perform bulk reads and writes.
D-Stream [Zaharia, 2013] (or Spark Streaming) is an add-on to the Spark engine and is based on the idea of treating streaming computations as series of short interval batch computations. Because it is based on RDDs the process is also deterministic, so lost data can be recomputed without replication and in parallel with the active computations. Consistency is ensured by atomically processing each record within the time interval in which it arrives. Spark streaming inter-operates efficiently with Spark’s batch features. Users can express ad-hoc queries and use the same high level API for processing both historical and streaming data.
One issue with the system is that it does not scale linearly. With many nodes the number of stragglers also increases, which in turn affects the overall performance. Also Spark Streaming supports only the point-to-point pattern compared to other systems, which can operate using broadcast or all-to-one aggregations. There are also other modules and possible improvements that the authors highlight such as enabling asynchrony, version tracking or correctness debugging.
Data cleaning [top]
One of the most common probabilistic models is the Kalman filter, a stochastic and recursive data filtering algorithm which models the value of a sensor as a function of its previous value. Naive Bayes and Markov chains are also proposed in [Elnahrawy, 2003] [Chu, 2005] to identify anomalies. Inferring missing values can also contribute to the quality of processing sensor streams since these values can represent a base for indicating the precision of raw sensor values.
Outliers can be detected using statistical approaches (parametric, non-parametric), nearest neighbour or clustering. A detailed taxonomy of outlier detection methods is presented in [Zhang, 2010].
Declarative cleaning refers to the capability of using SQL-like interfaces with complex background cleaning algorithms. One such interface is proposed in [Mayfield, 2010]. Their aim is to hide the complexity of the cleaning process and expose a friendlier interface to non-experts.
Much of the work on compression and filtering is intended for indexing purposes and less for discovering patterns. Such examples include Fourier transformations [Agrawal, 1993] and approximating functions [Chakrabarti, 2002].
For trend discovery wavelet coefficients are used in [Papadimitriou, 2004]. Other work includes finding representative trends [Indyk, 2000] (a sub-sequence of the time series with the smallest sum of distances from all other equal sub-sequence), motifs [Chiu, 2003] (frequently repeated subsequence), vector quantization, change detection [Ide, 2005] or compressed sensing (a signal processing technique for efficiently acquiring and reconstructing a signal)
Dimensionality reduction can be split into feature selection (find a subset of variables) and feature extraction (transforms data into a high-dimensional space or fewer dimensions). The most well-known technique for dimensionality reduction is the Principal Component Analysis (PCA). PCA converts a set of observations into of possible correlated variables into a set of sorted principal components (uncorrelated variables). The first component has the largest variance.
Processing, storing, and sharing large amount of data [top]
Runtime Environments for Big Data High level languages (i.e., for parallel programming) have been a holy grail for computer science research, but lately researchers made a lot of progress in the area of runtime environments. There is much similarity between parallel and distributed run times, with both supporting messaging with different properties (several such choices are presented in Figure 1, for different hardware and software models). The hardware support of parallelism/concurrency varies from shared memory multicore, closely coupled clusters, and higher-latency (possibly lower bandwidth) distributed systems. The coordination (communication/synchronization) of the different execution units vary from threads (with shared memory on cores), MPI (between cores or nodes of a cluster), workflow or mash-ups linking services together, and the new generation of data intensive programming systems typified by Hadoop (implementing MapReduce) or Dryad.
Figure 1. Combinations of processes/threads and intercommunication mechanisms [Fox, 2010].
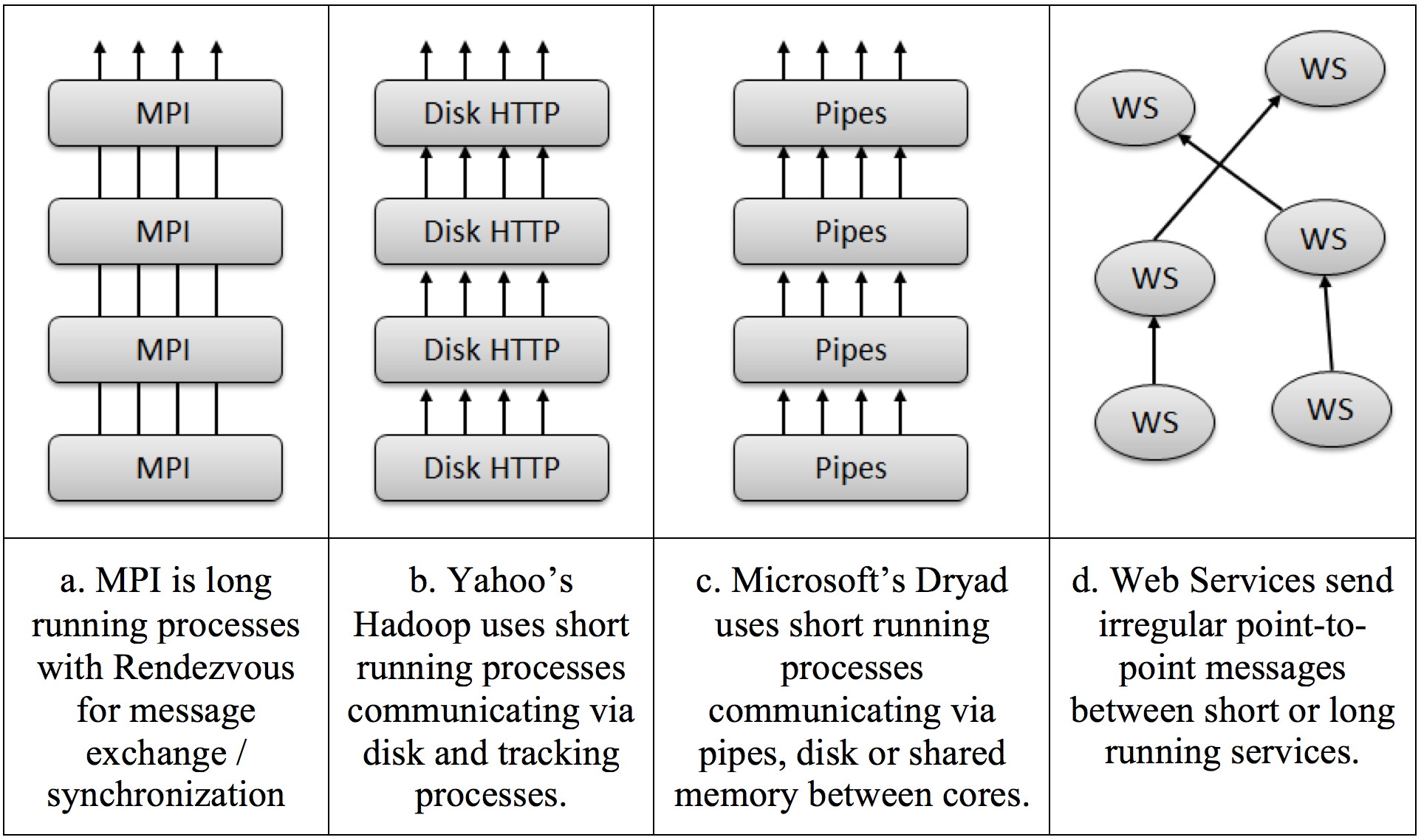
Short running threads can be spawned up in the context of persistent data in memory and have modest overhead [Fox, 2010]. Short running processes (i.e., implemented as stateless services) are seen in Dryad and Hadoop. Also, various runtime platforms implement different patterns of operation. In Iteration-based platforms, the results of one stage are iterated many times. This is typical of most MPI style algorithms. In Pipelining-based platforms, the results of one stage (e.g., Map or Reduce operations) are forwarded to another. This is functional parallelism typical of workflow applications.
An important ambiguity in parallel/distributed programming models/runtimes comes from the fact that today both the parallel MPI style parallelism and the distributed Hadoop/Dryad/Web Service/Workflow models are implemented by messaging. This is motivated by the fact that messaging avoids errors seen in shared memory thread synchronization.
MPI is a perfect example of runtimes crossing different application characteristics. MPI gives excellent performance and ease of programming for MapReduce, as it has elegant support for general reductions. However, it does not have the fault tolerance and flexibility of Hadoop or Dryad. Further MPI is designed for local computing; if the data is stored in a compute node’s memory, that node’s CPU is responsible for computing it. Hadoop and Dryad combine this idea with the notion of taking the computing to the data. A (non-comprehensive) presentation of technologies in use today for Big Data processing is presented in Figure 2.
Figure 2. Example of an ecosystem of Big Data analysis tools and frameworks.
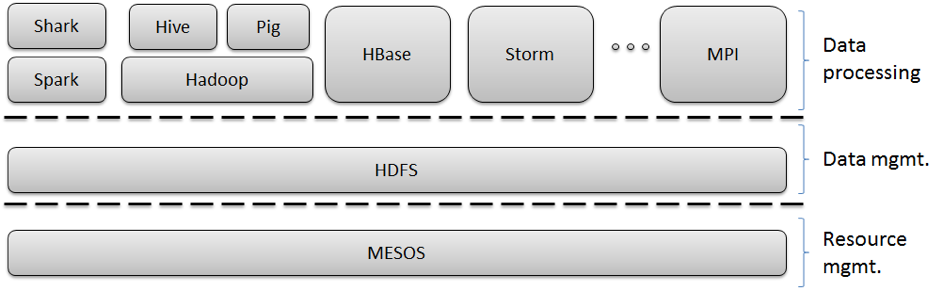
MapReduce programing model [top]
MapReduce (MR) emerged as an important programming model for large-scale data-parallel applications [Dean, 2008]. The MapReduce model popularized by Google is attractive for ad-hoc parallel processing of arbitrary data, and is today seen as an important programming model for large-scale data-parallel applications such as web indexing, data mining and scientific simulations, as it provides a simple model through which users can express relatively sophisticated distributed programs.
MapReduce breaks a computation into small tasks that run in parallel on multiple machines, and scales easily to very large clusters of inexpensive commodity computers. A MR program consists only of two functions, called Map and Reduce, written by a user to process key/value data pairs. The input data set is stored in a collection of partitions in a distributed file system deployed on each node in the cluster. The program is then injected into a distributed processing framework and executed in a manner to be described.
A key benefit of Map Reduce is that it automatically handles failures, hiding the complexity of fault-tolerance from the programmer. If a node crashes, MapReduce automatically reruns its tasks on a different machine. Similarly, if a node is available but is performing poorly, a condition called a straggler, MapReduce runs a speculative copy of its task (also called a ``backup task’’) on another machine to finish the computation faster. Without this mechanism (known as ``speculative execution’’ – not to be confused still with speculative execution at the OS or hardware level for branch prediction), a job would be as slow as the misbehaving task. In fact, Google has noted that in their implementation speculative execution can improve job response times by 44% [Dean, 2008].
Google's MapReduce implementation is coupled with a distributed file system named Google File System (GFS) [Ghemawat, 2012] from where it reads the data for MapReduce computations, and in the end stores the results. According to J. Dean et al., in their MapReduce implementation [Dean, 2008], the intermediate data are first written to the local files and then accessed by the reduce tasks.
The popular open-source implementation of MapReduce, Hadoop [Zaharia, 2008], is developed primarily by Yahoo, where it runs jobs that produce hundreds of terabytes of data. Today Hadoop is used at Facebook, Amazon, etc. Researchers are using Hadoop for short tasks where low response time is critical: seismic simulations, natural language processing, mining web data, and many others. Hadoop includes several specific components, such as its own file system, HDFS. In HDFS, data is spread across the cluster (keeping multiple copies of it in case of hardware failures). The code is deployed in Hadoop to the machine that contains the data upon which it intends to operate on. HDFS organizes data by keys and values; each piece of data has a unique key and a value associated with that key. Relationships between keys can be defined only within the MapReduce application.
Other solutions related to MapReduce [top]
Later on, mostly to alleviate the burden of having to re-implement repetitive tasks, the MapReduce community is migrating high-level languages on top of the current interface to move such functionality into the run time. Pig [Olston and Hive [Thusoo, 2010] are two notable projects in this direction. Such domain-specific languages, developed on top of the MapReduce model to hide some of the complexity from the programmer, today offer a limited hybridization of declarative and imperative programs and generalize SQL’s stored-procedure model. Some whole-query optimizations are automatically applied by these systems across MapReduce computation boundaries. However, these approaches adopt simple custom type systems and prove limited support for iterative computations.
An alternative tool on top of Hadoop is being developed by Facebook. Hive lets analysts crunch data atop Hadoop using something very similar to the structured query language (SQL) that has been widely used since the 80s. It is based on concepts such as tables, columns and partitions, providing a high-level query tool for accessing data from their existing Hadoop warehouses [Thusoo, 2010]. The result is a data warehouse layer built on top of Hadoop that allows for querying and managing structured data using a familiar SQL-like query language, HiveQL, and optional custom MapReduce scripts that may be plugged into queries. Hive converts HiveQL transformations to a series of MapReduce jobs and HDFS operations and applies several optimizations during the compilation process.
The Hive data model is organized into tables, partitions and buckets. The tables are similar to RDBMS tables and each corresponds to an HDFS directory. Each table can be divided into partitions that correspond to sub-directories within an HDFS table directory and each partition can be further divided into buckets, which are stored as files within the HDFS directories.
It is important to note that Hive was designed for scalability, extensibility, and batch job handling, not for low latency performance or real-time queries. Hive query response times for even the smallest jobs can be of the order of several minutes and for larger jobs, may be on the order of several hours. Also, today Hive is the Facebook’s primary tool for analyzing the performance of online ads, among other things.
Pig, on the other hand, is a high-level data-flow language (Pig Latin) and execution framework whose compiler produces sequences of Map/Reduce programs for execution within Hadoop [Olston, 2008]. Pig is designed for batch processing of data. It offers SQL-style high-level data manipulation constructs, which can be assembled in an explicit dataflow and interleaved with custom Map- and Reduce-style functions or executables. Pig programs are compiled into sequences of Map-Reduce jobs, and executed in the Hadoop Map-Reduce environment.
Pig’s infrastructure layer consists of a compiler that turns (relatively short) Pig Latin programs into sequences of MapReduce programs. Pig is a Java client-side application, and users install locally – nothing is altered on the Hadoop cluster itself. Grunt is the Pig interactive shell. With the support of this infrastructure, among the important advantages of Pig we mention the optimized data reading performance, the semi-structured data, and modular design. However, several limitations should not be ignored, such as the large amount of boiler-plate Java code (although proportionally less than Hadoop), the effort for learning how to use Pig and the lack of debugging techniques.
Spark is a framework that supports such applications while retaining the scalability and fault tolerance of MapReduce [Zaharia, 2010]. Spark provides two main abstractions for parallel programming: resilient distributed datasets and parallel operations on these datasets (invoked by passing a function to apply on a dataset).
Resilient distributed datasets (RDDs) are read-only collections of objects partitioned across a set of machines that can be rebuilt if a partition is lost. Users can explicitly cache an RDD in memory across machines and reuse it in multiple MapReduce-like parallel operations {zaharia2012resilient}. RDDs achieve fault tolerance through a notion of lineage: if a partition of an RDD is lost, the RDD has enough information about how it was derived from other RDDs to be able to rebuild just that partition.
Spark is implemented in Scala, a statically typed high-level programming language for the Java VM, and exposes a functional programming interface similar to DryadLINQ. Spark can also be used interactively, and allows the user to define RDDs, functions, variables and classes and use them in parallel operations on a cluster. According to experiments [Zaharia, 2010], by making use extensively of memory storage (using the RDD abstractions) of cluster nodes, most of the operations Spark can outperform Hadoop by a factor of ten in iterative machine learning jobs, and can be used to interactively query a large dataset with sub-second response time.
Twister is another MapReduce extension, designed to support iterative MapReduce computations efficiently [Ekanayake. Twister uses a publish/subscribe messaging infrastructure for communication and data transfers, and supports long running map/reduce tasks, which can be used in “configure once and use many times” approach. In addition, it provides programming extensions to MapReduce with “broadcast” and “scatter” type data transfers. It also allows long-lived map tasks to keep static data in memory between jobs in a manner of “configure once, and run many times”. Such improvements allow Twister to support iterative MapReduce computations highly efficiently compared to other MapReduce runtimes.
Dryad is a general-purpose distributed execution engine for coarse-grain data-parallel applications [Isard, 2007]. While MapReduce was designed to be accessible to the widest possible class of developers (aiming for simplicity at the expense of generality and performance), the Dryad system allows the developer fine control over the communication graph as well as the subroutines that live at its vertices. A Dryad application developer can specify an arbitrary directed acyclic graph to describe the application’s communication patterns, and express the data transport mechanisms (files, TCP pipes, and shared-memory FIFOs) between the computation vertices.
Dryad runs the application by executing the vertices of this graph on a set of available computers, communicating as appropriate through files, TCP pipes, and shared-memory FIFOs. The vertices provided by the application developer are quite simple and are usually written as sequential programs with no thread creation or locking. Concurrency arises from Dryad scheduling vertices to run simultaneously on multiple computers, or on multiple CPU cores within a computer. The application can discover the size and placement of data at run time, and modify the graph as the computation progresses to make efficient use of the available resources.
Dryad is designed to scale from powerful multi-core single computers, through small clusters of computers, to data centers with thousands of computers. The Dryad execution engine handles all the difficult problems of creating a large distributed, concurrent application: scheduling the use of computers and their CPUs, recovering from communication or computer failures, and transporting data between vertices.
DryadLINQ is a system and a set of language extensions that enable a programming model for large scale distributed computing [Yu, 2008]. It generalizes execution environments such as SQL, MapReduce, and Dryad in two ways: by adopting an expressive data model of strongly typed .NET objects; and by supporting general-purpose imperative and declarative operations on datasets within a traditional high-level programming language. A DryadLINQ application is a sequential program (hence, the programmer is given the “illusion” of writing for a single computer), composed of LINQ (Language Integrated Query) expressions performing imperative or declarative operations and transformations on datasets, and can be written and debugged using standard .NET development tools. Objects in DryadLINQ datasets can be of any .NET type, making it easy to compute with data such as image patches, vectors, and matrices. DryadLINQ programs can use traditional structuring constructs such as functions, modules, and libraries, and express iteration using standard loops. Crucially, the distributed execution layer employs a fully functional, declarative description of the data-parallel component of the computation, which enables sophisticated rewritings and optimizations like those traditionally employed by parallel databases. The DryadLINQ system automatically and transparently translates the data-parallel portions of the program into a distributed execution plan, which is passed to the Dryad execution platform, which further ensures efficient, reliable execution of this plan.
Sharing the data [top]
Sharing the data is another challenge for Big Data applications, besides processing. With all the BigData tools and instruments available, we are still far from understanding all the complexities behind processing large amounts of data. Recent projects such as BigQuery have the potential to encourage scientists to put their data into the Cloud, where potentially others might have access as well. BigQuery is a tool developed by Google to allow ordinary users run ad hoc queries using an SQL-like syntax. Google had used previously the tool (under the name Dremel) internally for years before releasing a form of it in their generally available service - BigQuery - capable to get results in seconds from terabytes of data [Vrbic, 2012]. The tool is hosted on Google's infrastructure. Its main advantage is simplicity: compared to Hadoop, which requires set up and administration, companies can take their data, put it in Google's cloud, and use it directly into their applications.
Similarly, Facebook is building Prism [Roush, 2013], a platform currently rolling out across the Facebook infrastructure. The typical Hadoop cluster is governed by a single “namespace” and a list of computing resources available for each job. In opposition, Prism carves out multiple namespaces, creating many “logical clusters” that operate atop the same physical cluster. Such names spaces can then be divided across various Facebook teams, and all of them would still have access to a common dataset that can span multiple data centers.
Nexus is a low-level substrate that provides isolation and efficient resource sharing across frameworks running on the same cluster, while giving each framework freedom to implement its own programming model and fully control the execution of its jobs [Hindman, 2009]. As new programming models and new frameworks emerge, they will need to share computing resources and data sets. For example, a company using Hadoop should not have to build a second cluster and copy data into it to run a Dryad job. Sharing resources between frameworks is difficult today because frameworks perform both job execution management and resource management. For example, Hadoop acts like a “cluster OS” that allocates resources among users in addition to running jobs. To enable diverse frameworks to coexist, Nexus decouples job execution management from resource management by providing a simple resource management layer over which frameworks like Hadoop and Dryad can run.
Mesos is a thin resource sharing layer that enables fine-grained sharing across diverse cluster computing frameworks, by giving frameworks such as Hadoop or Dryad a common interface for accessing cluster resources [Hindman. To support a scalable and efficient sharing system for a wide array of processing frameworks, Mesos delegates control over scheduling to the framework themselves. This is accomplished through an abstraction called a “resource offer”, which encapsulates a bundle of resources that a framework can allocate on a cluster node to run tasks. Mesos decides how many resources to offer each framework, based on an organizational policy such as fair sharing, while frameworks decide which resources to accept and which tasks to run on them. While this decentralized scheduling model may not always lead to globally optimal scheduling, in practice its developers found that it performs surprisingly well in practice, allowing frameworks to meet goals such as data locality nearly perfectly [Hindman, 2011]. In addition, resource offers are simple and efficient to implement, allowing Mesos to be highly scalable and robust to failures.